针对大模型的性能测试 对大型语言模型进行性能测试,通常需要从 模型能力 和 推理效率 这两个核心维度来衡量。一个全面的测试体系,需要结合衡量“智能”的学术基准与评估“速度”的 ... continue reading AI 大模型 zhuoyuebiji 2026/4/16 215
国产热门模型注册送 tokens/代金券(OpenClaw 龙虾费 tokens, 免费的薅一薅,有代金券) 【智普GLM】 🚀 速来拼好模,智谱 GLM Coding 超值订阅,邀你一起薅羊毛!Claude Code、Cline 等 20+ 大编程工具无缝支持,“码力”全开,越拼越爽!立即开拼,享限时惊喜价!链接:h ... continue reading AI 大模型 zhuoyuebiji 2026/3/18 195
机器学习和自然理解任务中的 Query、Ground Truth、Context 在机器学习和自然理解任务中,Query(查询)、Ground Truth(真值标签)、Context(上下文) 是三个核心概念,尤其是在检索增强生成(RAG)、问答系统、信息检索等场景中。 1. Query(查询) 是什么 ... continue reading AI 大模型 zhuoyuebiji 2026/4/8 195
Obsidian 和 dify 做知识库的对比,哪个更适合落地到企业软件测试流程中 Obsidian 和 Dify 在构建知识库时,定位和核心能力有显著区别。简单来说,Obsidian 是一个强大的个人知识管理工具,而 Dify 是一个面向企业的应用开发与知识运营平台。 将两者对比后,Dify 更适合落地到企业软件测 ... continue reading AI 大模型 zhuoyuebiji 2026/4/17 194
针对大模型的安全性测试 大模型是有可能生成事实性错误的输出,我们不应依赖其提供事实准确的信息。还有 预训练模型及微调数据集的局限性,大模型也有可能生成低俗、带有偏见或其他冒犯性的内容。所以测试工程师需要对大模型做安全性测试,根据最新的行业实践和标准建立一个系统化的 ... continue reading AI 大模型 zhuoyuebiji 2026/4/14 190
如何判断测试各岗位人员的主动性 一、测试管理人员 工作方面 前瞻性规划:主动制定测试战略、优化测试体系,而非被动应对 风险识别:主动识别团队和项目的质量风险,并提前制定应对措施 能力建设:主动规划团队能力提升路径,关 ... continue reading 软件测试 zhuoyuebiji 2026/3/2 182
全力推进和落地 AI QA 工作流 一、AI QA 工作流是什么? 简单说:用 AI 替代 / 辅助传统人工测试,把 “质量保障” 全流程自动化、智能化。核心不是 “用 AI 写几条用例”,而是覆盖需求→用例&r ... continue reading 软件测试 zhuoyuebiji 2026/4/28 164
测试任务提测标准和流程 提测标准的核心目标是:确保交付给测试团队的版本具备“可测性”和“基本稳定性”。 标准覆盖开发自测、文档完备性、代码质量、功能完整性等维度。 通过建立结构化、可量化的提测规范,并辅以 ... continue reading 软件测试 zhuoyuebiji 2026/5/7 126
测试岗年终总结方向参考 【2025年,是公司产品与技术架构持续深化演进的一年。作为高级软件测试工程师,我始终以“保障产品高质量交付、驱动研发效能提升”为核心目标,在复杂系统测试、质量体系建设与团队赋能等维度深耕细作。现将本年度工作总结与未来 ... continue reading 软件测试 zhuoyuebiji 2026/5/7 122
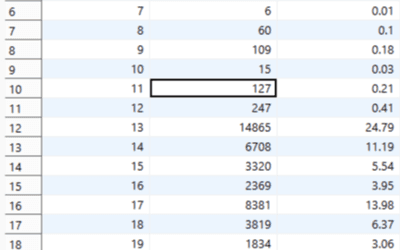
抽奖日志表统计中奖的次数和奖品出现的概率 抽奖日志表结构 -- game.smelt_log definition CREATE TABLE `smelt_log` ( `id` bigint NOT NULL AUTO_INCREMENT, `user ... continue reading 软件测试 zhuoyuebiji 2026/5/7 118